/ 10
Summary
This review breaks down where ScrapeOps delivers real operational value, where its platform still feels narrow, and which developer teams are most likely to benefit from its proxy aggregation and monitoring stack.
Pros
Cons
ScrapeOps Review Scores
ScrapeOps Review: Web Scraping Infrastructure Without the Vendor Juggling
ScrapeOps is not a no-code scraping app or an AI agent that magically pulls clean data from the internet. It is developer infrastructure for teams already running scrapers and tired of babysitting proxies, parser breakage, scheduling, and job visibility. That distinction matters. ScrapeOps looks strongest when scraping is already part of your workflow and the pain is operational, not conceptual.
What Is ScrapeOps?
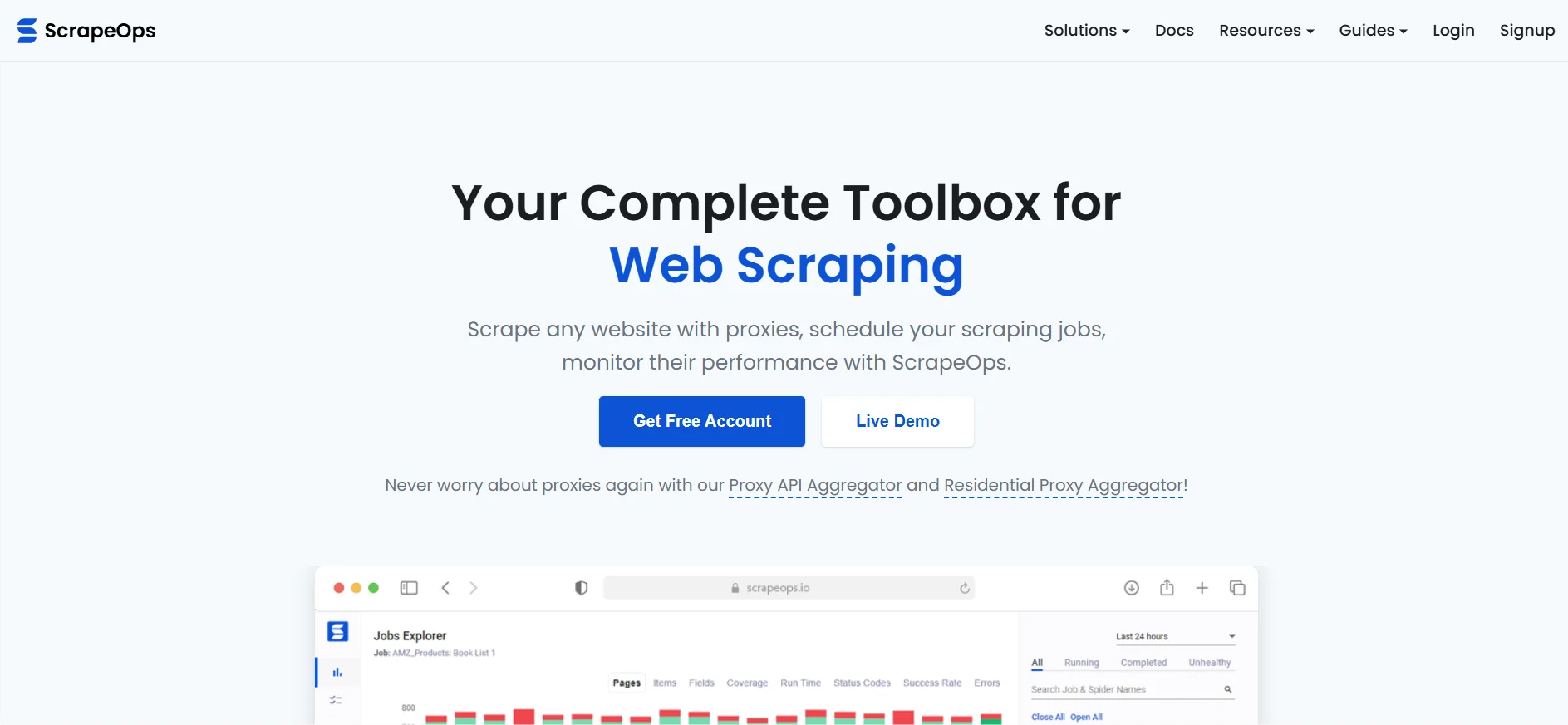
ScrapeOps is a web scraping DevOps platform built around four main jobs: proxy aggregation, scraper monitoring, job scheduling, and HTML-to-JSON parsing.
The simple version: it helps developers keep production scrapers alive.
Instead of buying and managing several proxy providers separately, ScrapeOps gives users one proxy endpoint that routes requests through multiple providers. Instead of manually checking whether Scrapers are failing, it adds monitoring, alerts, and job health tracking. Instead of constantly rewriting parsers for large ecommerce or listing sites, its Parser API can return structured JSON for supported targets.
The category is best described as web scraping infrastructure. The AI Scraper Builder adds an AI-assisted code-generation layer, but calling ScrapeOps an AI agent platform would be misleading. The core product is still plumbing for developers.
That is not a weakness. It is the product’s real lane.
How Does ScrapeOps Work?
ScrapeOps plugs into existing scraping workflows rather than replacing them.
A developer can use the Proxy API by routing requests through ScrapeOps with an API key. From there, ScrapeOps handles provider selection, retries, IP rotation, and anti-bot routing depending on the plan and target. For teams already dealing with proxy bans, that is the obvious value: one endpoint instead of a pile of proxy accounts and duct-taped fallback logic.
Monitoring requires deeper integration. Scrapy users can add the SDK with a small settings change, while Python Requests users need to wire in the integration manually. Once connected, ScrapeOps tracks pages scraped, items extracted, errors, status codes, runtimes, and success rates. Alerts can go out through email, Slack, or webhook when jobs degrade.
Scheduling and server management sit on top of that. Users can connect servers by SSH, link GitHub repositories, deploy code, trigger jobs, and manage runs from the dashboard. This is useful if your scraping fleet is spread across machines and cron jobs are turning into a quiet liability.
The Parser API works differently. Users send raw HTML to ScrapeOps, and the platform returns structured JSON for supported sites such as Amazon, Walmart, eBay, Indeed, Redfin, and search engines. That is valuable, but only if your target sites fit the supported parser list.
The AI Scraper Builder is newer and less proven. It takes sample URLs and generates Python or Node.js scraper code using frameworks such as BeautifulSoup, Scrapy, Selenium, Playwright, Cheerio, Axios, or Puppeteer. Useful, yes. Fully mature, maybe not. It is still in beta, and beta scraper generation should be treated as a starting point, not production truth.
Key Features
- ScrapeOps’s most important feature is the Proxy API Aggregator. It turns a messy operational problem into a cleaner routing layer. Teams can access multiple proxy providers from one endpoint instead of manually switching between vendors when ban rates spike or performance drops.
- The Residential and Mobile Proxy Aggregator is the heavier version of that idea. It supports HTTP and SOCKS5, country and city targeting, sticky sessions, rotating proxies, and bandwidth-based pricing. For teams that need location-specific scraping, this matters more than generic proxy access.
- The monitoring product is the second big piece. Scraping failures are rarely dramatic. They usually rot slowly: item counts drop, HTML changes, blocks rise, or jobs start returning junk. ScrapeOps gives teams a dashboard and alerting layer so those failures become visible earlier.
- The Parser API is narrower but practical. If you scrape supported sites, maintained parsers can save real engineering time. The value is not “AI extraction.” The value is not having your team rewrite selectors every time a retail page changes layout.
- The AI Scraper Builder is the most headline-friendly feature, but not necessarily the most important one. Generating boilerplate scrapers from sample URLs can speed up early work, especially for product pages and category pages. The catch is obvious: generated scraper code still needs review, testing, and maintenance. Anyone pretending otherwise is selling fairy dust.
- The MCP server is interesting but under-explained publicly. Until the use cases and tool exposure are clearer, it should be treated as an early signal rather than a buying reason.
Setup and Onboarding
ScrapeOps has a split personality on setup.
For proxy access, onboarding looks light. Get an API key, route requests through the endpoint, and start testing. That is the low-friction path.
For monitoring and scheduling, the product becomes more technical. Scrapy users get the easiest path because the integration is small. Python Requests users still have a reasonable setup curve. Teams using Node.js, Selenium, Playwright, or Puppeteer for monitoring do not get the same maturity yet, since those monitoring integrations are not fully released.
The bigger setup burden comes with scheduling and server management. SSH access, GitHub repository linkage, deployment permissions, and production job control are not casual onboarding steps. They are exactly where serious teams may see value, but also where non-technical users will bounce.
That is the real tradeoff: lightweight testing is easy, meaningful adoption requires developer ownership.
Real-World Use Cases
ScrapeOps fits best where scraping is already business-critical.
A Python developer running Scrapy spiders can use it to monitor job health without building an internal observability stack. That is probably the cleanest fit.
A data team scraping ecommerce sites can use the proxy aggregator to reduce vendor juggling and the Parser API to get structured product data from supported sites. This is practical for price monitoring, product intelligence, and marketplace tracking.0
A scraping contractor can use ScrapeOps as a cost-controlled proxy layer without committing to one vendor. That matters when client targets vary and one proxy provider does not perform equally well everywhere.
Teams running scrapers across several servers can use the dashboard to schedule, rerun, pause, and deploy jobs without relying on scattered cron jobs and manual SSH work.
The AI Scraper Builder fits earlier in the workflow: generating starter code from sample URLs. It is useful for getting moving faster, but it does not remove the need for engineering judgment.
Who Is ScrapeOps Best For?
ScrapeOps is best for Python-heavy scraping teams that already know what they are doing and want less operational mess.
It fits:
- Scrapy developers who need monitoring with minimal setup
- Data engineering teams managing multiple scraping jobs
- Contractors who need flexible proxy access across targets
- Ecommerce and marketplace intelligence teams scraping supported sites
- Small technical teams that need production scraping infrastructure without enterprise pricing
The sweet spot is not “anyone who wants web data.” The sweet spot is developers and teams already scraping enough that proxy failures, parser upkeep, and monitoring gaps are costing time.
Who Should Avoid ScrapeOps?
- Non-technical users should probably skip it. ScrapeOps does not remove the need to understand scraping, HTTP behavior, site structure, or deployment basics.
- Teams looking for a fully managed scraping service may also be disappointed. ScrapeOps wraps around scrapers you build and operate. It is not Apify-style actor marketplace convenience, and it is not a done-for-you data provider.
- Node.js-first teams should be cautious if monitoring is the main reason they are looking. Proxy access and AI code generation support Node.js workflows, but monitoring is still strongest on Python.
- Enterprise buyers needing public SLA detail, security certifications, data residency clarity, or deep compliance documentation may find the trust layer thin. That does not mean the product is unreliable. It means the evidence is not enough to underwrite enterprise confidence by itself.
Strengths
- The biggest strength is operational consolidation. Proxy management, monitoring, parser maintenance, and scheduling are separate headaches. ScrapeOps pulls several of them into one practical dashboard.
- The free tiers are unusually useful. Proxy credits, residential bandwidth, parser credits, and free monitoring lower the cost of evaluation. That matters in scraping, where sales demos mean less than seeing whether a target actually works.
- Pricing clarity is another real advantage. Standard plans are public, entry prices are accessible, and teams can understand the pricing model before talking to sales.
- Scrapy support is a strong wedge. A three-line setup for monitoring is exactly the kind of adoption path developers actually tolerate.
- The proxy aggregator also has a sharp buyer benefit: it reduces dependence on one provider. In scraping, vendor lock-in is not just commercial risk. It is operational risk.
Weaknesses
- The biggest weakness is stack coverage. Monitoring is still Python-centered. If your production scraping runs on Node.js or headless browser frameworks, the platform’s monitoring story is not as convincing yet.
- Parser coverage is also narrow. Amazon, Walmart, eBay, Indeed, Redfin, and search engines are useful targets, but that is not a universal parsing layer. If your important sites sit outside that list, you are back to maintaining parsers yourself.
- The AI Scraper Builder is promising but undercooked as a decision driver. Beta access, limited schemas, and uncertain performance on complex pages make it a useful experiment, not a core reason to buy.
- Third-party validation is thin. A small number of public reviews is not enough to make strong claims about reliability at scale. For serious deployments, teams should run their own target-specific tests before committing.
- Enterprise trust signals are also light. Public pages do not prominently show the kind of security, compliance, SLA, or data-retention detail larger companies often need. That gap matters more as scraping volume and internal risk exposure increase.
Pricing and Plans
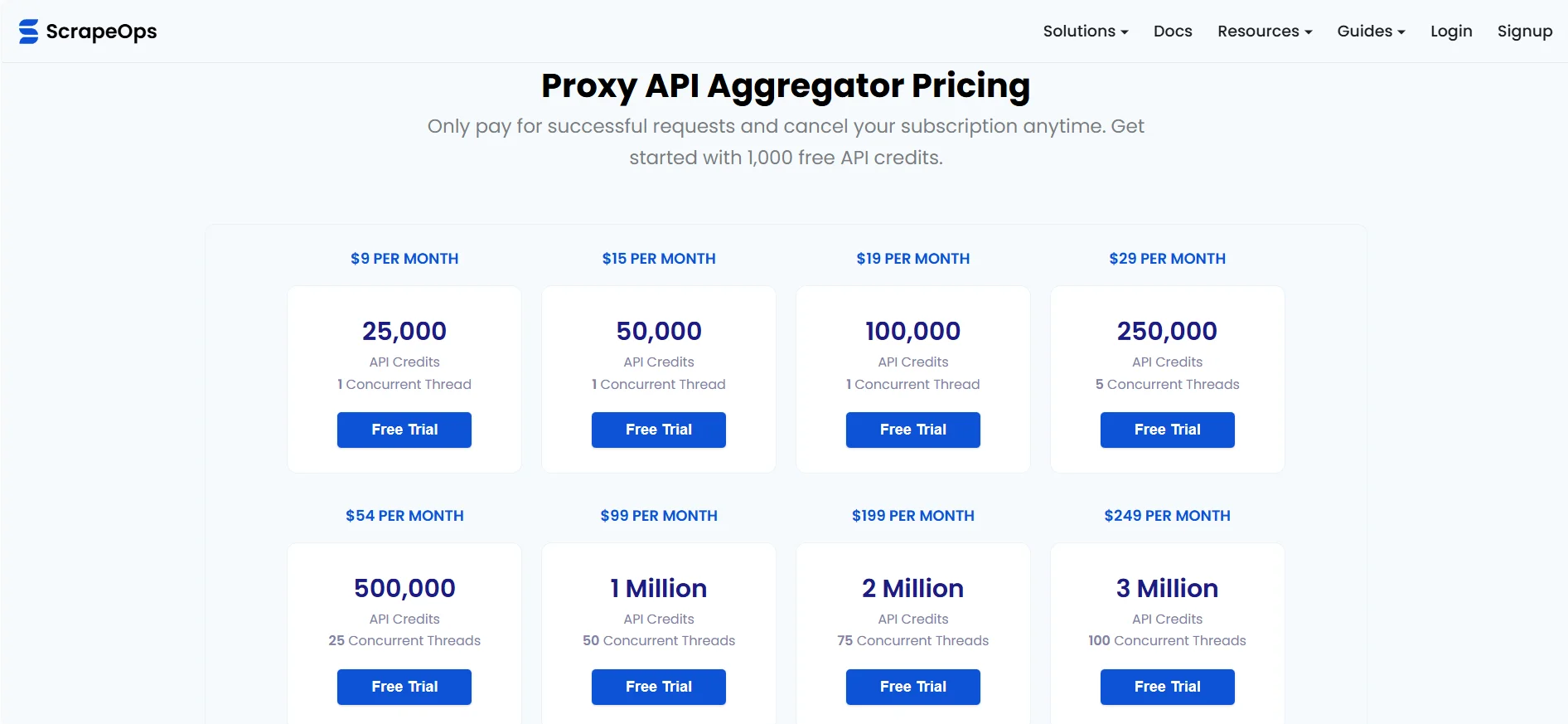
ScrapeOps pricing is clearer than most scraping infrastructure vendors.
The Proxy API Aggregator starts at $9 per month, with higher tiers scaling by API credits. The Residential Proxy Aggregator starts with a free 100MB tier and paid plans from $15 per month. Monitoring has a free community plan, then paid plans from $4.95 per month. Parser API plans start at $5 per month.
The pricing model depends on the product:
- Proxy API pricing is based on successful request credits.
- Residential proxy pricing is based on bandwidth.
- Monitoring pricing is based on page volume and feature tier.
- Parser API pricing is based on successful parses.
This makes sense, but it also means teams need to understand their usage pattern before estimating monthly spend. A team doing light monitoring may spend almost nothing. A team scraping high-volume ecommerce pages through residential proxies will care much more about bandwidth and success rates.
The packaging is strongest for developers and small teams because the entry points are low and the free tiers are real enough to test. Enterprise pricing is less transparent because custom plans require contact.
How ScrapeOps Compares With Alternatives
ScrapeOps sits in a different lane from many obvious alternatives.
- Compared with Zyte, ScrapeOps looks lighter and more modular. Zyte offers a broader managed scraping stack, including cloud scraping infrastructure. ScrapeOps is better framed as a toolkit around scrapers you already run. If you want more managed infrastructure, Zyte may be the more natural comparison. If you want proxy aggregation plus monitoring without a heavier platform commitment, ScrapeOps has a cleaner pitch.
- Compared with ScraperAPI, ScrapeOps is broader. ScraperAPI is mainly a proxy and scraping API product. ScrapeOps includes proxy aggregation, but adds monitoring, scheduling, parser APIs, and a dashboard around production scraper operations. ScraperAPI may appeal more to teams that want a single-vendor proxy API. ScrapeOps is more compelling when redundancy and observability matter.
- Compared with Bright Data, ScrapeOps is more accessible but less enterprise-heavy. Bright Data is a large proxy and data collection platform with deeper enterprise positioning. ScrapeOps aggregates access to providers like Bright Data rather than replacing that entire category. For smaller technical teams, that can be the point.
- Compared with Apify, the difference is workflow ownership. Apify gives users managed actors, a marketplace, cloud runs, and datasets. ScrapeOps expects users to own the scraper logic and infrastructure. Apify is easier for teams that want prebuilt scraping workflows. ScrapeOps is better for teams already writing their own scrapers and wanting infrastructure support.
Final Verdict
ScrapeOps is worth testing if you already run production scrapers and the messy parts are starting to tax your team: proxy switching, monitoring blind spots, parser maintenance, and scattered job scheduling.
It is not the right tool for non-technical users, casual scraping needs, or teams expecting a fully managed data extraction service. It also should not be bought on the AI Scraper Builder alone. That feature may become useful, but the mature value is still in scraping infrastructure.
The strongest fit is a Python-heavy scraping team that wants better operational control without buying into a large enterprise platform. The main tradeoff is maturity breadth: ScrapeOps is sharp in its core lane, but some newer or broader pieces still need stronger documentation, more integrations, and more public validation.
For the right developer team, ScrapeOps deserves a shortlist. For everyone else, it may be more infrastructure than they actually want.
FAQ
- What is ScrapeOps used for?
ScrapeOps is used to manage production web scraping infrastructure. Its main use cases include proxy aggregation, scraper monitoring, job scheduling, server management, and parsing HTML into structured JSON for supported websites.
- Is ScrapeOps a no-code scraping tool?
No. ScrapeOps is developer-focused. Users still need to build and run their own scrapers, although the AI Scraper Builder can generate starter scraper code for some use cases.
- Who should use ScrapeOps?
ScrapeOps is best for developers, data teams, and scraping contractors running Python, Scrapy, or Requests-based scrapers in production. It is especially useful when proxy reliability, monitoring, and parser maintenance are becoming operational problems.
- Does ScrapeOps offer a free plan?
Yes. ScrapeOps has multiple free entry points, including proxy credits, residential proxy bandwidth, parser credits, and a free community monitoring plan.
- What are the main alternatives to ScrapeOps?
Relevant alternatives include Zyte, ScraperAPI, Bright Data, Apify, and Scrapfly. The right choice depends on whether the user wants managed scraping, proxy access, scraper hosting, marketplace actors, or developer infrastructure around existing scrapers.
Disclosure: This article may contain affiliate links. If you sign up through them, Coin360 may earn a commission at no extra cost to you. That does not affect our editorial standards, and reviews are written to prioritize accuracy, usefulness, and reader value.